
図面やドキュメントのデータを活用する難しさ
設計者は、図面からプロジェクト報告書、議事録、竣工写真に至るまで、膨大な非構造データを扱っています。重要な情報がドキュメントや画像の中に埋もれていることも多く、必要なときに取り出して効率よく活用することが難しくなります。
実際、マッキンゼーでは以前から、ナレッジワーカーは週の約5分の1、つまり約9時間を情報探索に浪費していると推計しています。建設業界でいうと、これは設計や課題解決に充てられるはずの時間を浪費しており、結果として高コストな遅延やコミュニケーションの齟齬につながります。
さらに業界分析では、自由記述テキストや画像といった非構造コンテンツが、生成される全データの最大80%を占めるとされていますが、従来型のデータベースはこうしたデータを十分に活用することが難しく、価値ある情報がフォルダの奥に埋もれ、重複作業や回避可能なミスを生み出す可能性があります。
AEC業界では、図面・仕様書・メールなど多様な情報を抱えながら、それらを一元的に構造化・検索できる手段がないことも多く、この課題の解決を難しくする1つの要因となっています。
自然言語によるデータの抽出
こうした課題に対し、AIを活用した自然言語によるデータ抽出は、非構造なデータを紐解くための鍵となります。
従来、データ抽出の設定には専門的な知識が必要でした。スクリプトを書いたり、データベースのスキーマを定義したり、OCRテンプレートを設定したりと、IT専門家やデータエンジニアにしかできない作業が前提でした。自然言語ベースの抽出では、こうした障壁が取り払われます。
TektomeのKnowledgeBuilderは、「図面種別を抽出してください。この情報は通常、図面タイトルにあります。」といったプロンプトを入力できます。するとAIが図面を解析し、特定の情報を見つけ出してくるため、事前にスキーマ上で「図面種別」をフィールドとして定義しておく必要はありません。
あるテックライターは次のように述べています。
自然言語プロンプトを使えば、探している情報を、望む形式で簡単に抽出できる。
KnowledgeBuilderのアプローチは、まさにこの言葉の通り、人がデータを読み解くのと同じように、自然言語からAIが意図を理解し、どう取り出すかはシステムが判断して、必要なデータを取得します。
誰でもデータベースを構築できる理由
KnowledgeBuilderの強みは、ITやBIMの専門家だけでなく、誰もがデータを構造化し、データベースを構築できる点です。従来のシステムでは、プロジェクト情報のデータベースが欲しい場合、IT部門にスキーマ設定や独自の抽出ルール作成を依頼する必要があり、そのプロセスに数週間かかることもありました。新たな要件が出れば、また振り出しに戻り(そしてIT部門の順番待ちに戻り)ます。一方でKnowledgeBuilderは、自然言語による指示を可能にするため、担当者がその場で抽出したい情報を定義でき、コーディングもデータベース知識も不要です。
データベースの項目は、データを抽出する際の「あなたの質問」によって定義されるため、データ構造は柔軟かつユーザー主導になります。プロジェクト開始時に設定された項目に縛られず、必要に応じて任意のタイミングで新しい属性を追加できます。
これにより現場の担当者自身がデータ化できることで、プロジェクトとともに進化するカスタマイズ可能な独自のデータベースが構築されます。
図面から画像まで、さまざまなファイル形式に対応
AECのデータ抽出における大きな課題は、ファイル形式の多様さです。プロジェクトの知見は、整ったWord文書だけにあるわけではありません。スキャンされた図面、現場状況の写真、手書きスケッチ、メール、表が含まれるPDFなど、あらゆる形式に散在します。従来は、形式ごとに別々の処理が必要でした(例:スキャンにはOCR、手書きメモには手入力、など)。
KnowledgeBuilderは形式に依存しないよう設計されおり、同じ自然言語の指示で、ファイル形式を問わず、システムが適切に解釈します。これは基盤となるAIモデルがマルチモーダルであり、単一のプロンプトでテキストと画像の両方を入力として受け取り、文章と同様に図や写真も理解できるためです。
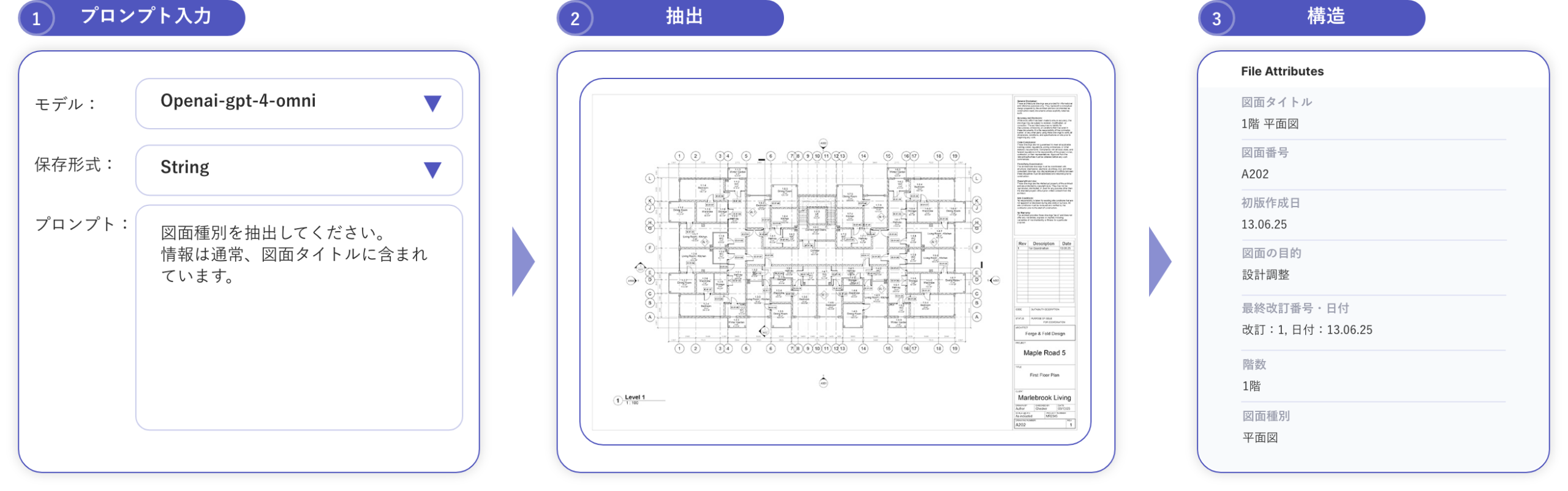
例:平面図の図面から、シンプルなプロンプトで構造化情報を抽出
タイムパフォーマンスの向上とミス削減
このアプローチによって、以下のような効率化が期待されます。
- タイムパフォーマンスの向上:以前なら数日〜数週間かかっていた手作業のデータ入力やドキュメント精査が、AIの自動処理により数秒〜数分で完了します。これにより、担当者は単純作業ではなく、設計・分析・意思決定といった価値の高い業務に時間を使えます。ある業界レポートでは、従業員の約70%が、複数システムにまたがる情報探索だけで週最大20時間を費やしていると報告されています。ドキュメントから自動でデータが投入される構造化データベースがあれば、この探し回る時間はほぼ解消され、クイックな検索で情報にアクセスできます。
- ミス削減による精度向上:人手によるデータ入力はミスが起こりやすく、一般的な手入力の誤り率は約1%程度だとする研究もあります。この数値は小さく見えますが、これが数千のデータポイントがある複雑なプロジェクトでは、深刻な問題につながり得ます(たとえば鉄骨梁サイズの入力ミスや、図面改訂日の誤りなど)。AIで抽出を自動化すれば、入力し直しによるタイポ、ページの見落としによる欠落、手書きの読み間違いなどが起きにくくなり、ミスの削減に貢献します。
非構造データが使われる情報になるとき
図面やドキュメントが活用できない理由は、量や形式の問題ではありません。
それらを、長いあいだ一元的に構造化・検索できる手段がなかったことにあります。
自然言語でAIに指示を出せるようになることで、現場の担当者自身が、必要な情報をその場で整理し、使える形に変えられるようになります。
これにより建設業界特有の非構造データは、探し回って読む対象から、業務を進めるために使われる情報源へと変わっていきます。
その変化が、タイムパフォーマンスの向上やミスの削減といった、最初の課題につながっていくのです。
KnowledgeBuilderの考え方や具体的な機能については、製品ページで詳しく紹介しています。